前言
前篇介绍了Hadoop3.1.1伪分布式部署安装的方法,对于日常学习够用了,但真正在生产环境中,还是需要Hadoop全分布式的安装和部署。下面我们以4台虚拟服务器,来模拟搭建Hadoop全分布式环境。
4台服务器的角色分别如下:
| 服务器名 | 担当角色 |
|---|---|
| node01 | namenode |
| node02 | secondary namenode、datanode |
| node03 | datanode |
| node04 | datanode |
前提说明:服务器已配置好ip地址,并将节点名称(hostname)与ip映射已经在hosts文件中配置好,同时能够使用ping 节点名称的方式能够ping通。
详细配置过程如下:
1. 免秘钥ssh登录配置
ssh免秘钥登录已经在之前的博客中介绍,详情请参见《Hadoop3.1.1全分布式安装部署之SSH免秘钥登录》。
2. node01 配置Hadoop
上传hadoop-3.1.1.tar.gz至node01服务,并解压。
演示目录为/opt/hadoop/下。
配置步骤与伪分布式方式类似,主要配置etc/hadoop/hadoop-env.sh、etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml。具体配置信息如下:
①配置etc/hadoop/hadoop-env.sh,代码如下:
export JAVA_HOME=/usr/java/jdk1.8.0_181 #配置JDK路径请将JDK路径换成你服务器的路径
export HDFS_NAMENODE_USER=root #配置namenode用户
export HDFS_DATANODE_USER=root #配置datanode用户
export HDFS_SECONDARYNAMENODE_USER=root #配置secondary namenode用户
②配置etc/hadoop/core-site.xml,代码如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/full</value>
</property>
</configuration>
fs.defaultFS:配置namenode节点
hadoop.tmp.dir:临时目录,必须得修改,默认会存放在/tmp目录下,会导致数据丢失。
③配置etc/hadoop/hdfs-site.xml,代码如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:9868</value>
</property>
</configuration>
dfs.replication:配置副本数
dfs.namenode.secondary.http-address:secondary namenode节点路径
④配置etc/hadoop/workers代码如下:
node02
node03
node04
分别将node02,node03,node04作为datanode。
3. 分发文件至node02、node03、node04
scp -r /opt/hadoop/ root@node02:/opt/
scp -r /opt/hadoop/ root@node03:/opt/
scp -r /opt/hadoop/ root@node04:/opt/
4. 启动Hadoop集群
格式化文件系统
在node01节点上,输入:
bin/hdfs namenode -format

启动集群
sbin/start-dfs.sh
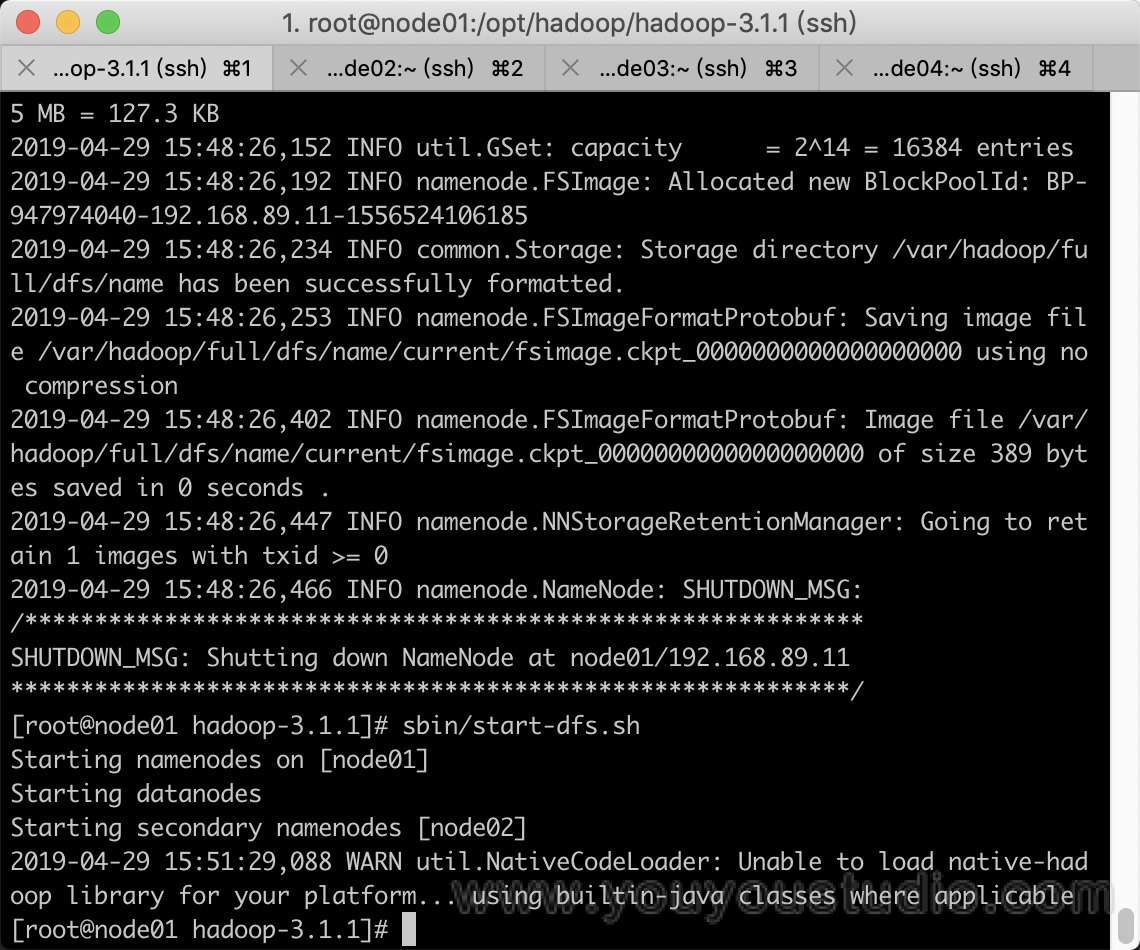
可以将bin目录及sbin目录配置进环境变量。
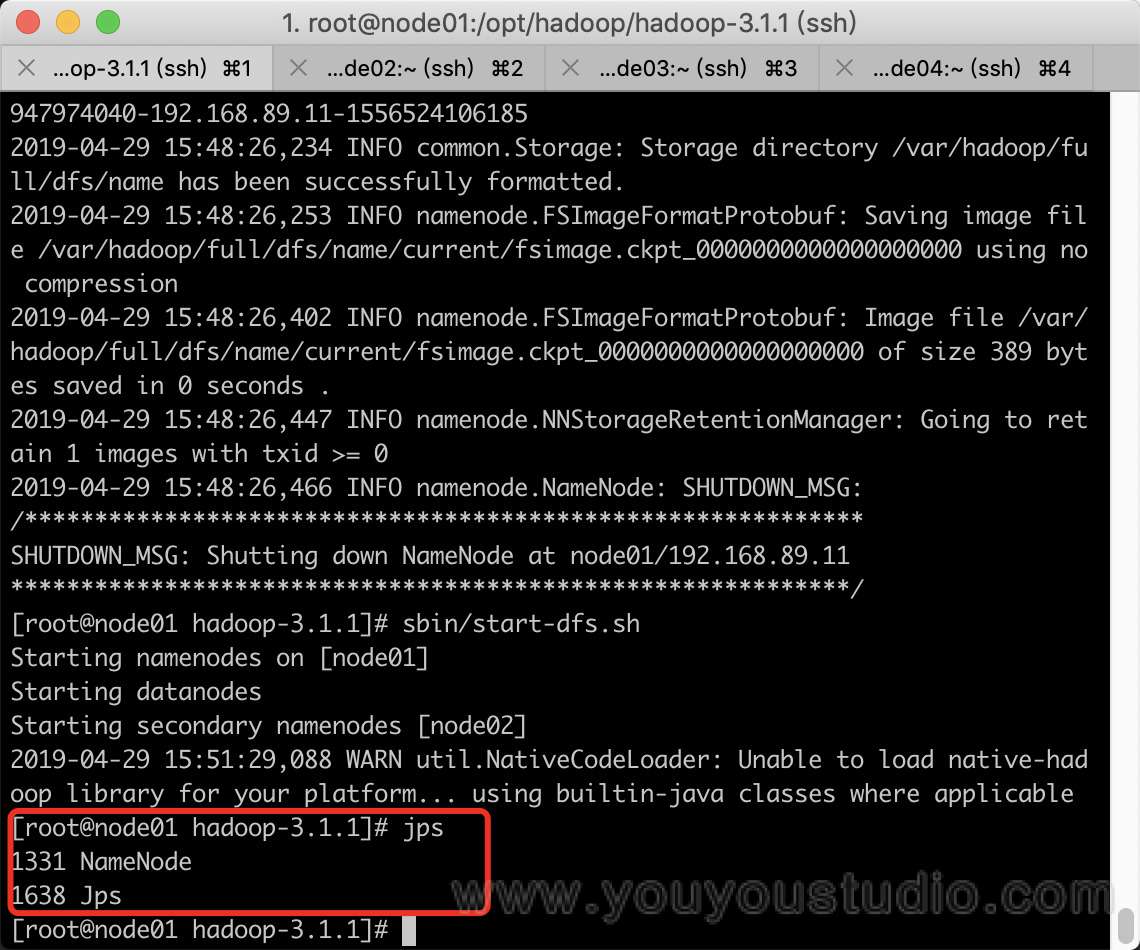
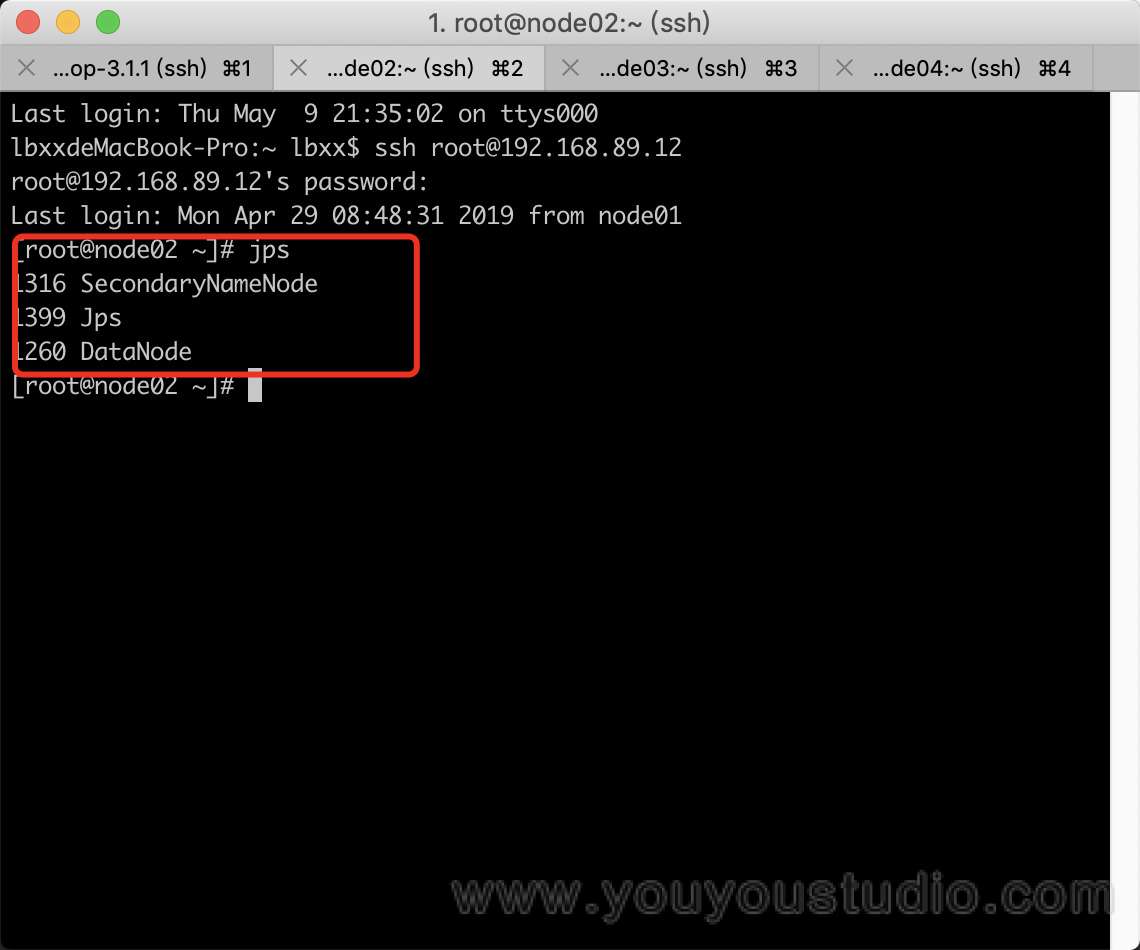
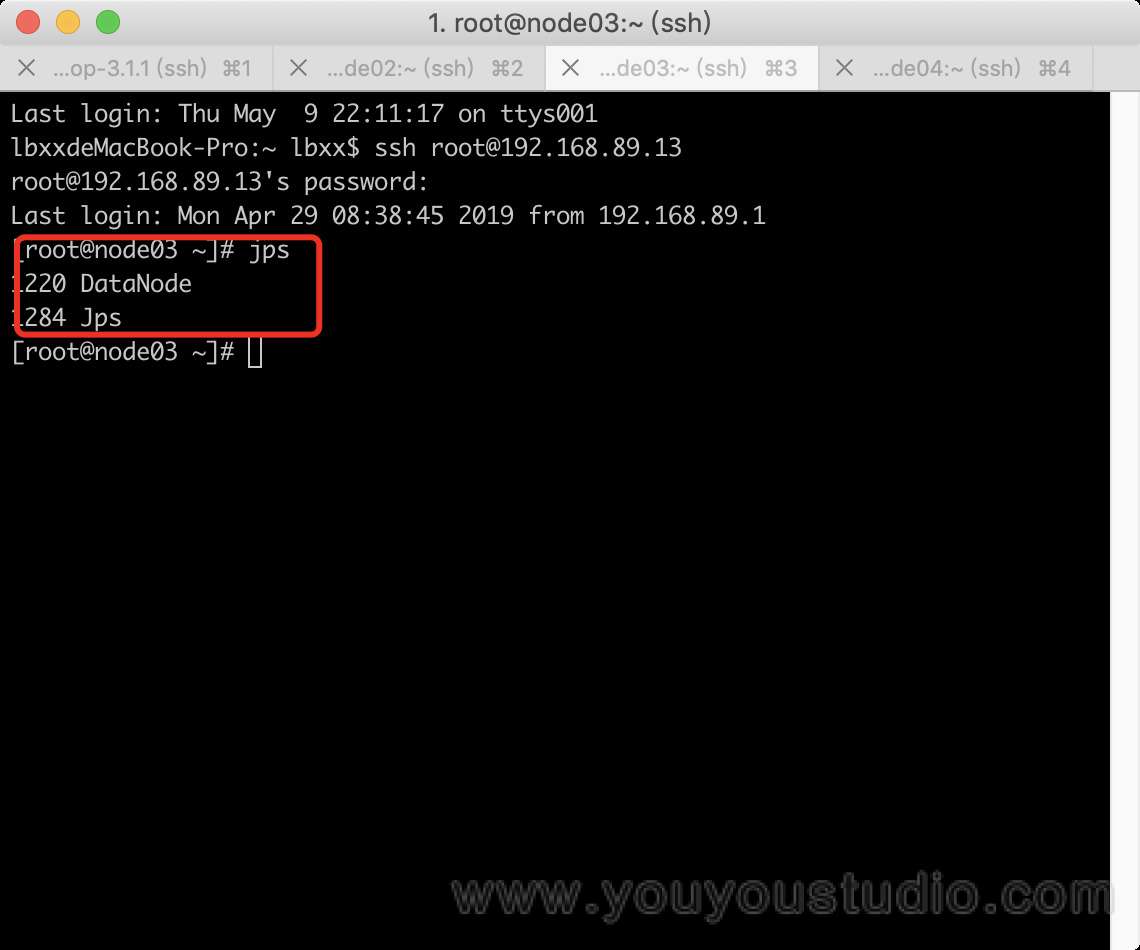
5. 查看效果
可以在各节点使用jsp命令,查看各节点进程:
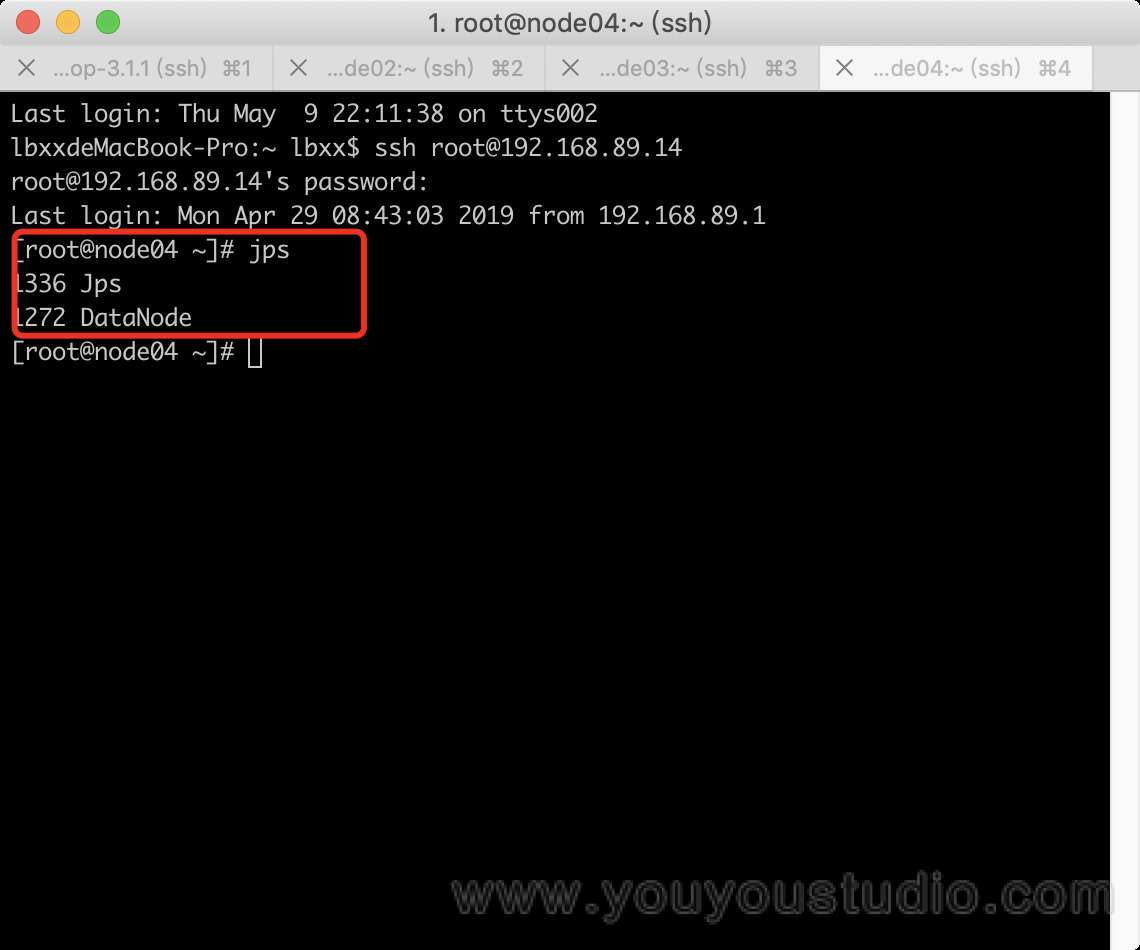
6. 总结
Hadoop3.1.1的全分布式安装部署与伪分布式安装部署非常类似,无非就是做了角色的分配。原来将所有角色都分配在node01上,现将各角色分配到不同的节点之上。
