前言
在学习大数据时,无可避免地会遇到Hadoop的安装部署。Hadoop部署可以使用伪分布式部署和全分布式部署。初学者,可以先练习伪分布式部署。
在Hadoop3.1.1进行伪分布式部署时,遇到了很多坑。现将完整的部署方式进行分享!其实官方文档和网上随便找的,都是有问题的。

本安装步骤是在Centos6.5环境下,Hadoop版本为3.1.1。Centos7基本也类似。
本次配置服务器节点名称为node01,如不做说明,则node01就代表服务器名。
具体步骤主要如下:
1. 安装JDK
Hadoop依赖JDK,因此在安装Hadoop之前,
必须确保服务器已经成功安装JDK。具体步骤就不展开了。如果连JDK都不会安装,我想,此说明文档不适合你。
2. 配置Hadoop
下载hadoop-3.1.1.tar.gz,并上传至服务器。
我上传路径为/opt/hadoop/目录下。
解压hadoop-3.1.1.tar.gz
tar -zxvf hadoop-3.1.1.tar.gz
以下操作,都是在/opt/hadoop/hadoop-3.1.1目录下进行。
①配置etc/hadoop/hadoop-env.sh
vi etc/hadoop/hadoop-env.sh
直接shift+g,跳转到文件末尾
追加如下代码:
export JAVA_HOME=/usr/java/jdk1.8.0_181 #配置JDK路径请将JDK路径换成你服务器的路径
export HDFS_NAMENODE_USER=root #配置namenode用户
export HDFS_DATANODE_USER=root #配置datanode用户
export HDFS_SECONDARYNAMENODE_USER=root #配置secondary namenode用户
保存并退出。
一般文档,都只讲配置JAVA_HOME,其他几项都不配置,其实一启动,就会报错。在3.0版本中,就需要指定这几个参数值。
②配置etc/hadoop/core-site.xml
vi etc/hadoop/core-site.xml
完整配置代码如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
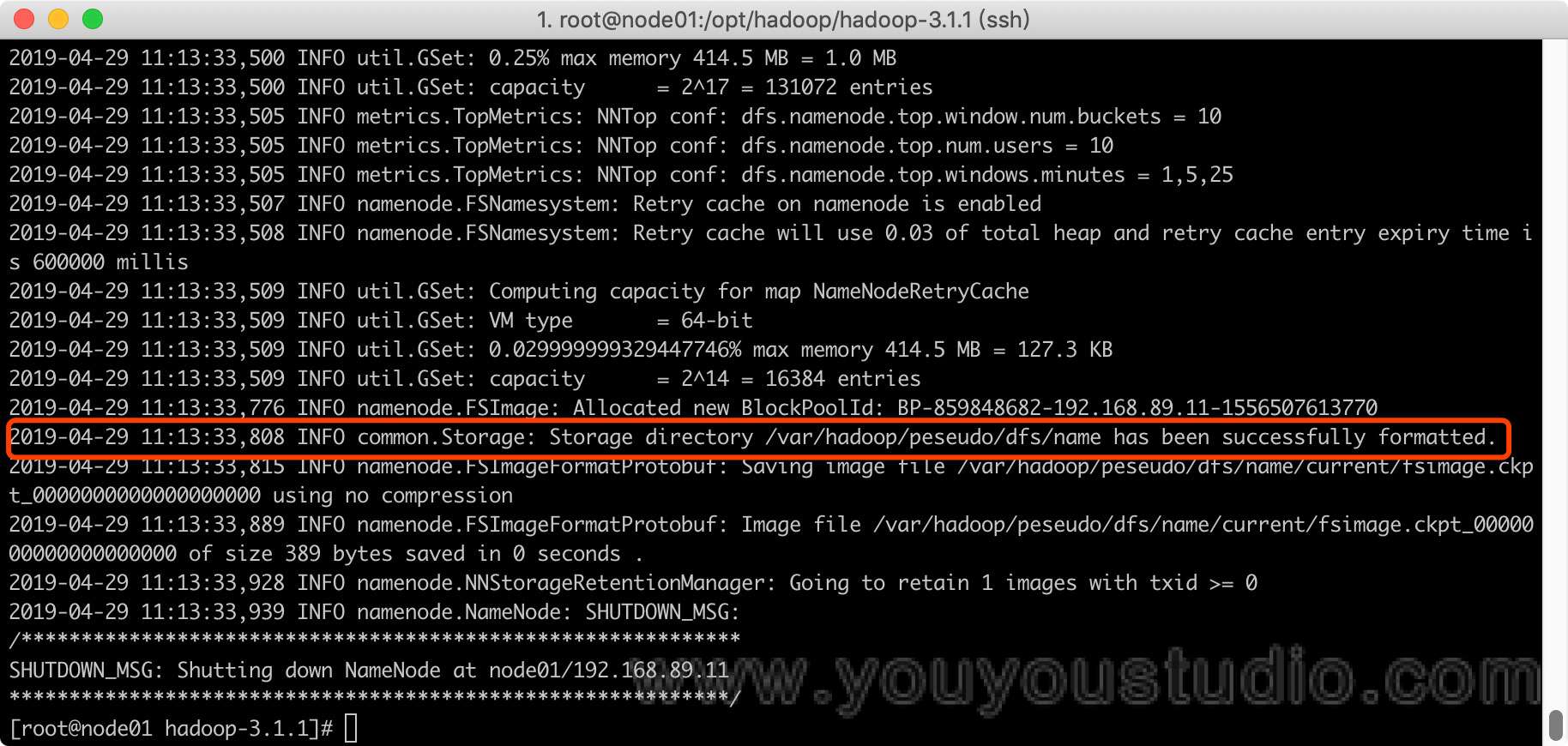
<value>/var/hadoop/peseudo</value>
</property>
</configuration>
除了需要配置节点地址之外,还需要配置tmp目录。主要原因是元数据保存的路径,也存放在此目录下。默认保存在系统的/tmp目录下,是极其危险的。
③配置etc/hadoop/hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
完整配置代码如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9868</value>
</property>
</configuration>
主要包括副本数和secondary节点的地址
④配置etc/hadoop/workers
vi etc/hadoop/workers
将localhost改成节点名称 node01
node01
3. 启动Hadoop
①格式化文件系统
bin/hdfs namenode -format
②启动
sbin/start-dfs.sh

其中:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable,其实只是警告,并不影响Hadoop的启动(当时一直以为没有启动成功,一直找这方面的问题解决办法,其实并不影响)。
使用jps,查看已经启动NameNode、DataNode、SecondaryNameNode三个角色,即表示成功。
总结
至此,Hadoop3.1.1伪分布式安装部署完毕。如有问题,请关注微信公众号,进行问题反馈。
