前言
通过前三章,我们已经使Hadoop集群拥有高可用(ha)能力。接下来,我们将开启YARN组件,为MapReduce计算做好准备。
YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
服务器节点角色配置如下:
| 节点名称 | 原角色 | 新增角色 |
|---|---|---|
| node01 | NN-1, ZKFC,JNN | |
| node02 | NN-2,DN,ZK,ZKFC,JNN | NM |
| node03 | DN,ZK,JNN | RS,NM |
| node04 | DN,ZK | RS,NM |
RS:为ResourceManager
NM:NodeManager
具体配置及操作如下所示:
1. 配置etc/hadoop/mapred-site.xml
vi etc/hadoop/mapred-site.xml
配置信息如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapreduce使用yarn作为调度框架。
2. 配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
配置信息如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
</configuration>
注意:此处的yarn.resourcemanager.cluster-id集群名称,与之前配置的hdf的namespace不能相同。
3. 配置yarn-env.sh
vi yarn-env.sh
配置代码如下:
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=yarn
export YARN_NODEMANAGER_USER=root
4. 分发配置文件至node02,node03,node04
cd etc/hadoop
scp mapred-site.xml yarn-site.xml yarn-env.sh root@node02:`pwd`
scp mapred-site.xml yarn-site.xml yarn-env.sh root@node03:`pwd`
scp mapred-site.xml yarn-site.xml yarn-env.sh root@node04:`pwd`
5. 启动yarn
start-yarn.sh
也可以重启整个hadoop集群:
start-all.sh
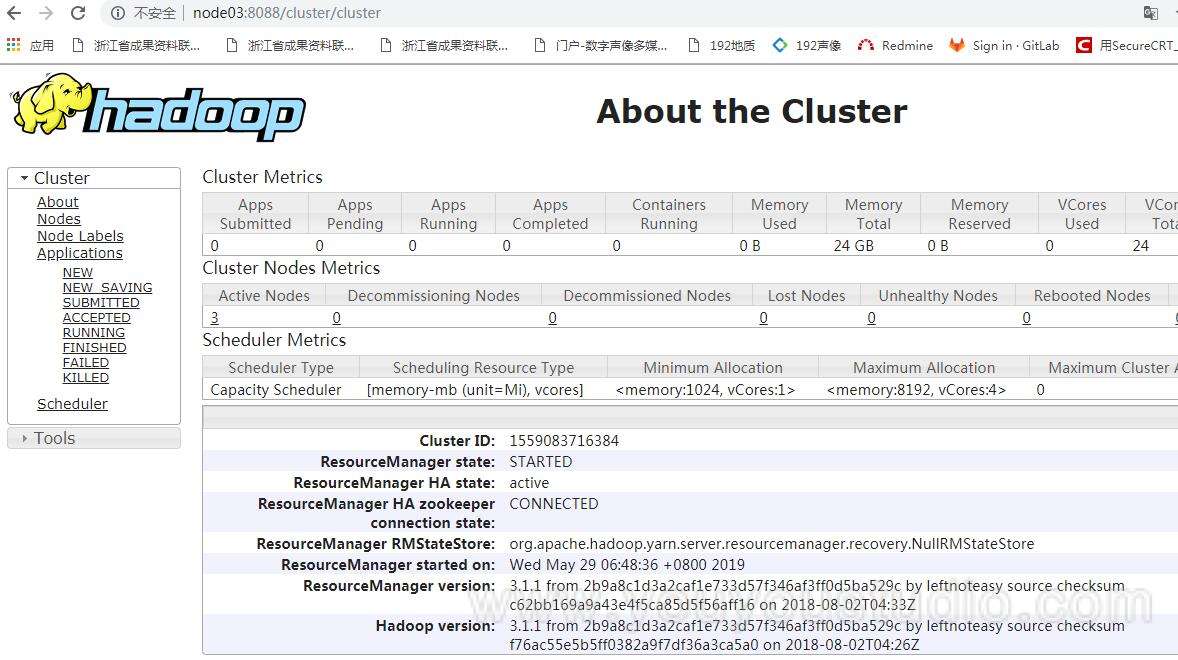
6. 踩坑
目前来看,集群是成功启动了,并且yarn也成功启动。
但是,当运行示例wordcount的时候,会报各种莫名其妙的错误。先将运行过程中,相关的错误一一进行排雷。
错误1:类无法加载
类似出现以下堆栈信息:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://node04:8088/cluster/
app/application_1559123047303_0002 Then click on links to logs of each attempt.. Failing the application.
主要原因是没有设置mapreduce的classpath。
classpath具体内容可以使用下面命令得到:
hadoop classpath
mapred-site.xml增加配置如下:
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop/hadoop-3.1.1/etc/hadoop:/opt/hadoop/hadoop-3.1.1/share/hadoop/common/lib/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/common/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/hdfs:/opt/hadoop/hadoop-3.1.1/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/hdfs/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/yarn:/opt/hadoop/hadoop-3.1.1/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-3.1.1/share/hadoop/yarn/*</value>
</property>
错误2:空指针
ERROR [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.NullPointerException
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.register(RMCommunicator.java:178)
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.serviceStart(RMCommunicator.java:122)
at org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator.serviceStart(RMContainerAllocator.java:280)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$ContainerAllocatorRouter.serviceStart(MRAppMaster.java:979)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.serviceStart(MRAppMaster.java:1293)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$6.run(MRAppMaster.java:1761)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.initAndStartAppMaster(MRAppMaster.java:1757)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.main(MRAppMaster.java:1691)
Caused by: java.lang.NullPointerException
at org.apache.hadoop.mapreduce.v2.app.client.MRClientService.getHttpPort(MRClientService.java:177)
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.register(RMCommunicator.java:159)
... 14 more
主要原因是没有配置yarn.resourcemanager.webapp.address.rm1和rm2服务器信息。默认配置端口号为8088,但在运行wordcount时,又要读取一遍,莫名其妙,看来老外也不靠谱。
在yarn-site.xml中增加如下代码:
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node03:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node04:8088</value>
</property>
总结
特别注意yarn.resourcemanager.cluster-id的配置,要与之前的配置的不一样。第一次配置的时候,这里配置错了,所以导致一直不成功。
还有一些坑,在实践过程中,往往需要花费更多的时间去解决。目前本人遇到了上述问题,希望对大家有帮助。
至此,已经为Hadoop3.1.1集群增加YARN组件。
